接上一节的选择最佳函数
达成目标

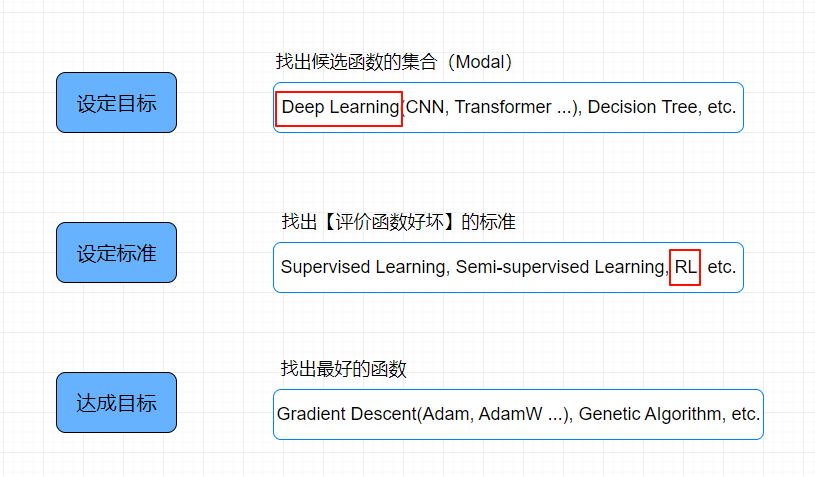
从最后的一个步骤开始说起
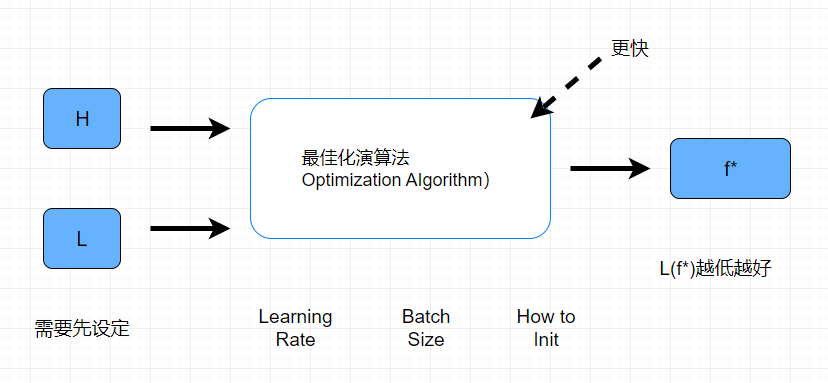
最佳化演算法看成一个大的函数,它做的事情就是传递一个预先定义好的H集合,它再传递一个之前评估函数好坏的标准L函数,输出一个最佳函数f,把函数代入到L函数中,它的值越小越好
其实也有另外一种期待就是它给出同样的H和L的时候,它跑的比较快找出答案
事实上,不是总是找出L(f*)的值是最低的,虽然不是最低的,但是是较低的
最佳化演算法它有很多提前设定, Learning Rate / Batch Size / How to Init (超参数(Hyperparameter)),这就是演算法调参
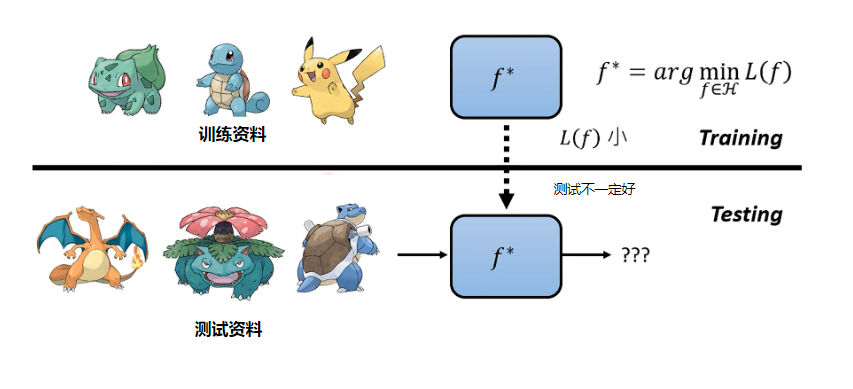
在Loss 上做额外考量(如: Regularizaiton)
设定范围

函数设定的范围不要太大,也不要太少,太大会圈到的不一定是好的函数,太小可能没有好的函数
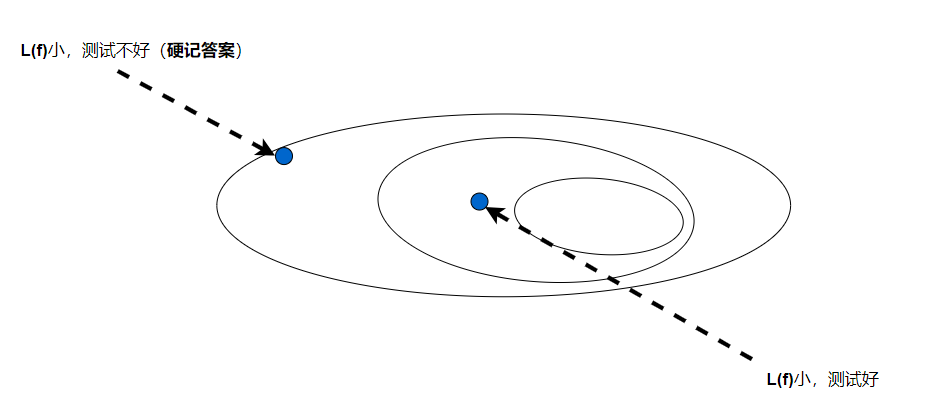
当训练的资料少的时候,划定的范围就要少,当训练资料多的时候,划定的范围可以大点,至于什么原因可以参考机器学习原理
有些方法它的好不是对当前目标结果好,而是为了提供其他面向的技术。比如下图,在内神经网络的结构网络里面有Residual Connection结构,在划定范围阶段来看,看不出来它又什么好处,但是它可以很容易从一堆函数集合中找出Loss值低的函数
