自督导式学习
ChatGPT背后的关键技术-预训练(Pre-train)
又叫自监督学习(Self-supervised Learning),又把预训练得到的模型称为基石模型(Foundation Model)
ChatGPT: chat:聊天 G: Generative 生成 P: Pre-trained 预训练 T:Transformer
督导式学习
一般机器是怎麼学习的?
以英文翻译中文为例子,它需要大量的中英文对照例子,机器会自动找出这个函数f,至于怎么找出的,后面会有介绍,函数的规则就会知道I=我,you=你,等等,然后给它一个句子,它就给出翻译。
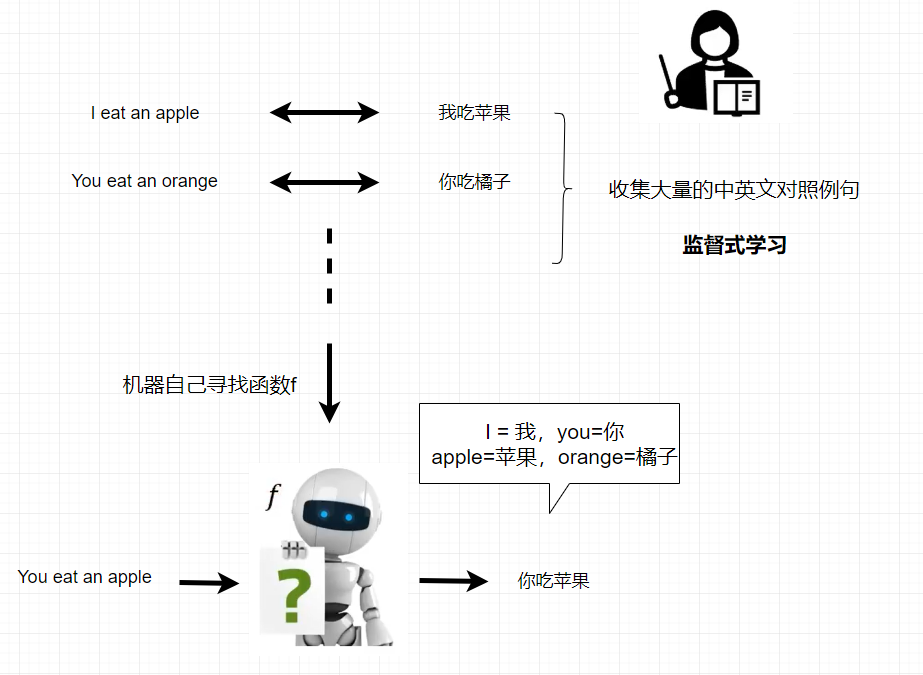
一般机器学习方式,又叫督导式学习。
如果把督导式学习套用到ChatGPT上
- 如下图提前准备好答案

- 机器自己寻找函数f
当输入是“全球最高山峰是哪座山峰?”的时候,根据上面的准备好的答案,输出“珠”的机率比较大,当输出"珠"之后,输出“穆”的机率比较大,有了这些输入资料之后,机器找到函数f,它给出的输出与人类给的输出是类似的。
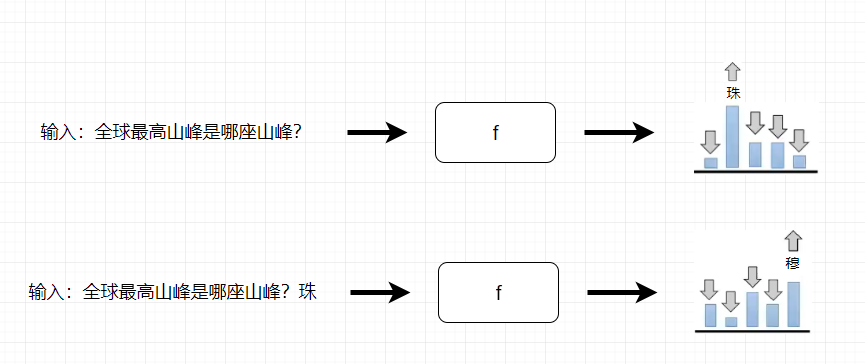
如果机器真的根据老师的教导找出函数f来,他的能力是非常有限的,人类老师可以提供的资料是有限的
如果上面的准备的问题没有提到"湖南最高的上是哪座上?" ,当你问到的时候,它就不知道怎么回答你。
- 需要无痛制造成对资料
网络上每一段文字都可以教机器做文字接龙
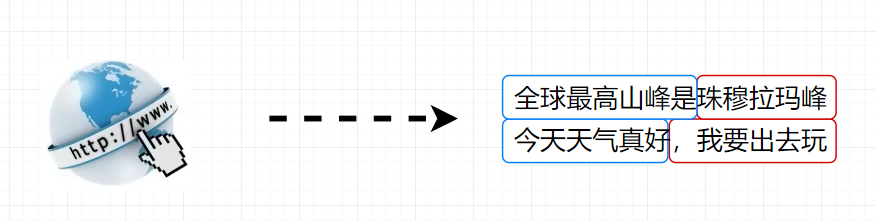
ChatGPT前身叫GPT,它的工作就是到网络上找大量资料,做文字接龙的事情

GPT-2当时是可以回答问题,并且正确率达到55%
问答:

摘要:

当年的结论:https://openai.com/blog/better-language-models/
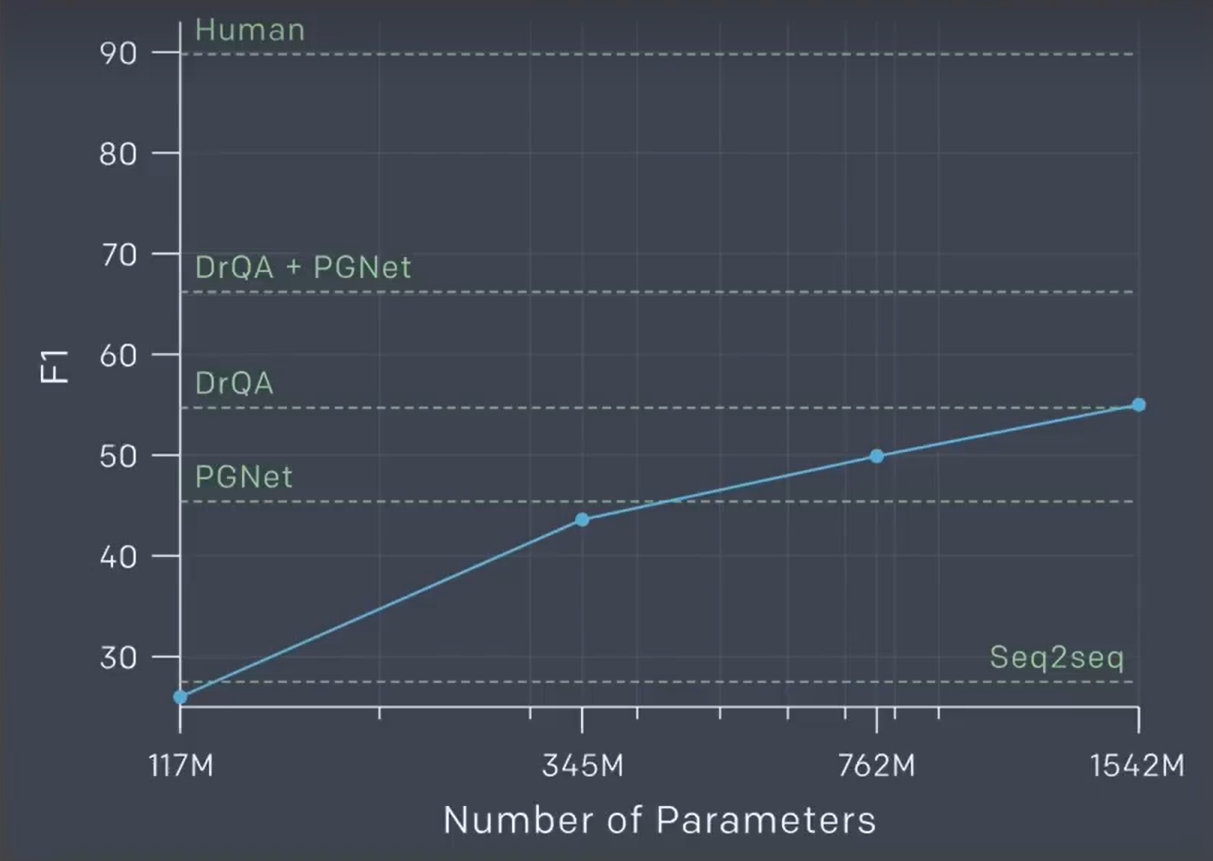
Human: 人类回答的正确率在90%
- GPT-3时代的来临

gpt3写代码
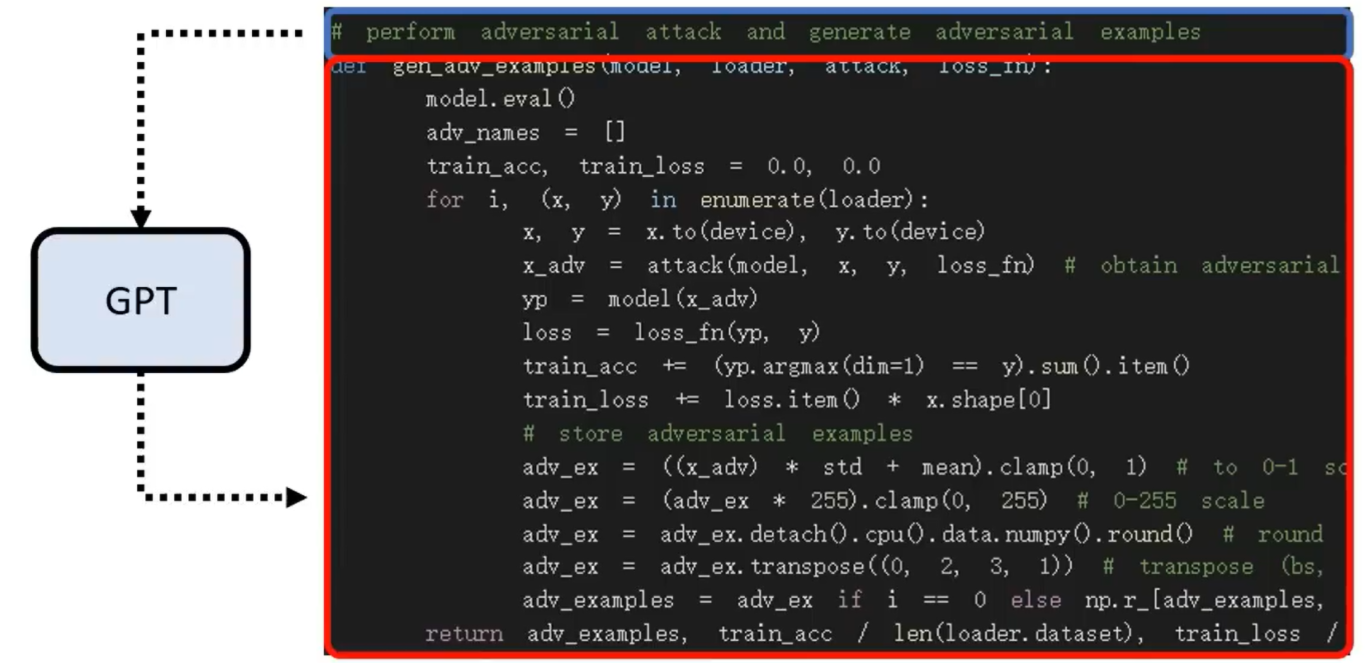
gpt3的能力上限
报告: https://arxiv.org/abs/2005.14165
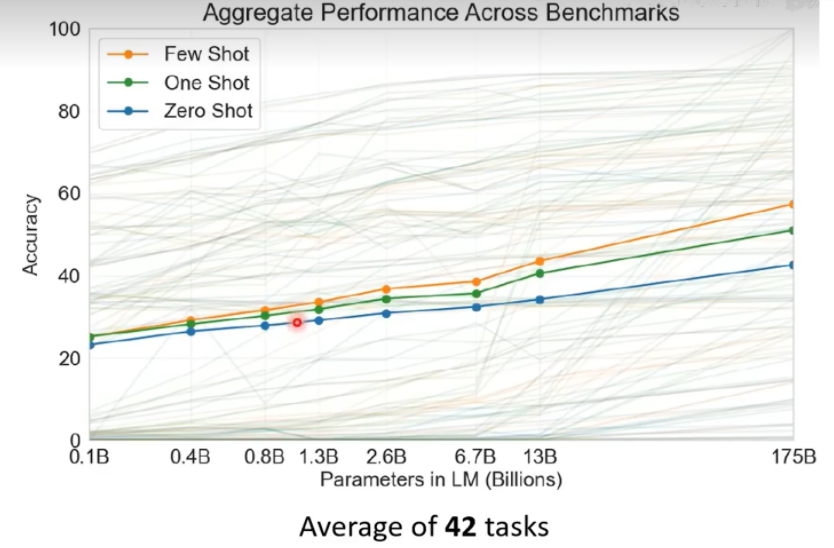
横轴:参数量 纵轴:正确率
可以看到参数量越大,准确率越高,但是从13B到175B,巨量的参数,但是感觉有上限
某种程度上说gpt3是不受控制的,比如下图所示:
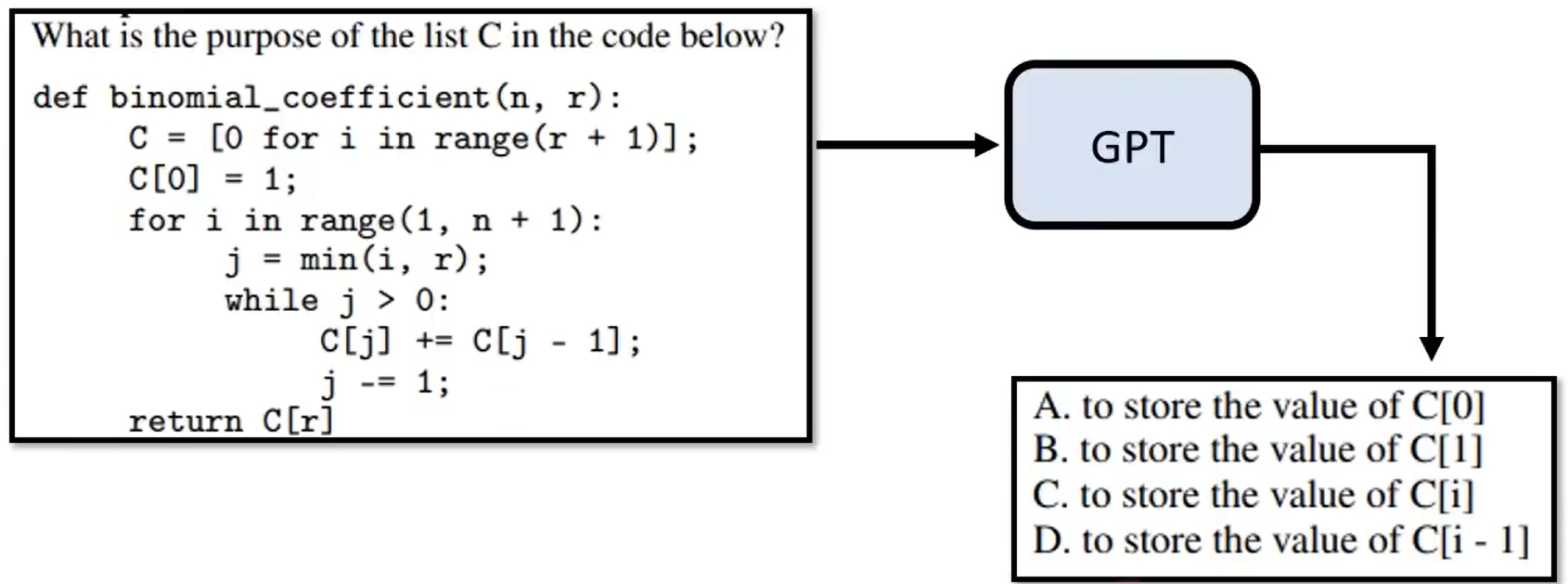
当问c这个list在这段代码里面有什么作用?它给你的回答是一个选择题, 因为它早在网络上爬取了这道题目,在很多时候,gpt3是不受控制的,虽然它能力很强
Source of image:https://arxiv.org/abs/2203.02155
增强式学习
- 如何强化gpt3呢?
此时就需要人工介入
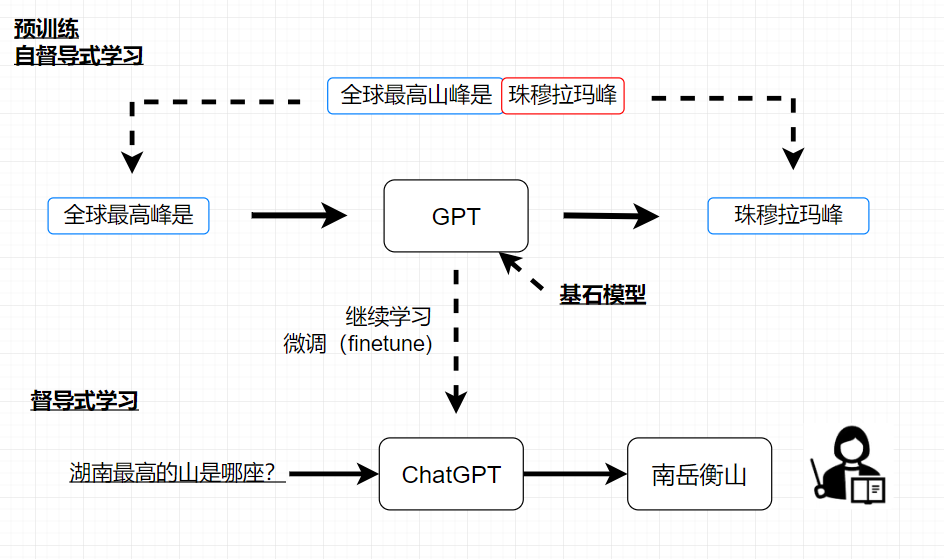
到gpt3是不需要人工干预的,到chatgpt才需要人工介入
chatgpt是经过督导式学习的结果
人类老师说,有人问湖南最高山是哪座,你回答他是南岳衡山
gpt透过人类老师提供的资料,继续学习,就变成了ChatGPT
经过督导式学习之前,是通过大量的网络资料学习的这个过程, 我们称为预训练, 又称为自督导式学习。
在自督导学习的过程中,也需要成对资料,是通过无痛生成的,通过无痛获取的成对资料,就称为自督导式学习
继续学习的过程,又称为微调(finetune);督导式学习是人类提供成对的资料,让机器进行学习
ChatGPT是由GPT产生出来的,这种通过GPT进行自督导式学习的生成的模型,又称为基石模型。那这里就清楚了,预训练或自督导式学习 与 基石模型讲的是同一件事情
预训练有多大的帮助呢?
在多種語言上做預訓練後,只要教某一個語言的某一個任務,自動學會其他語言的同樣任務
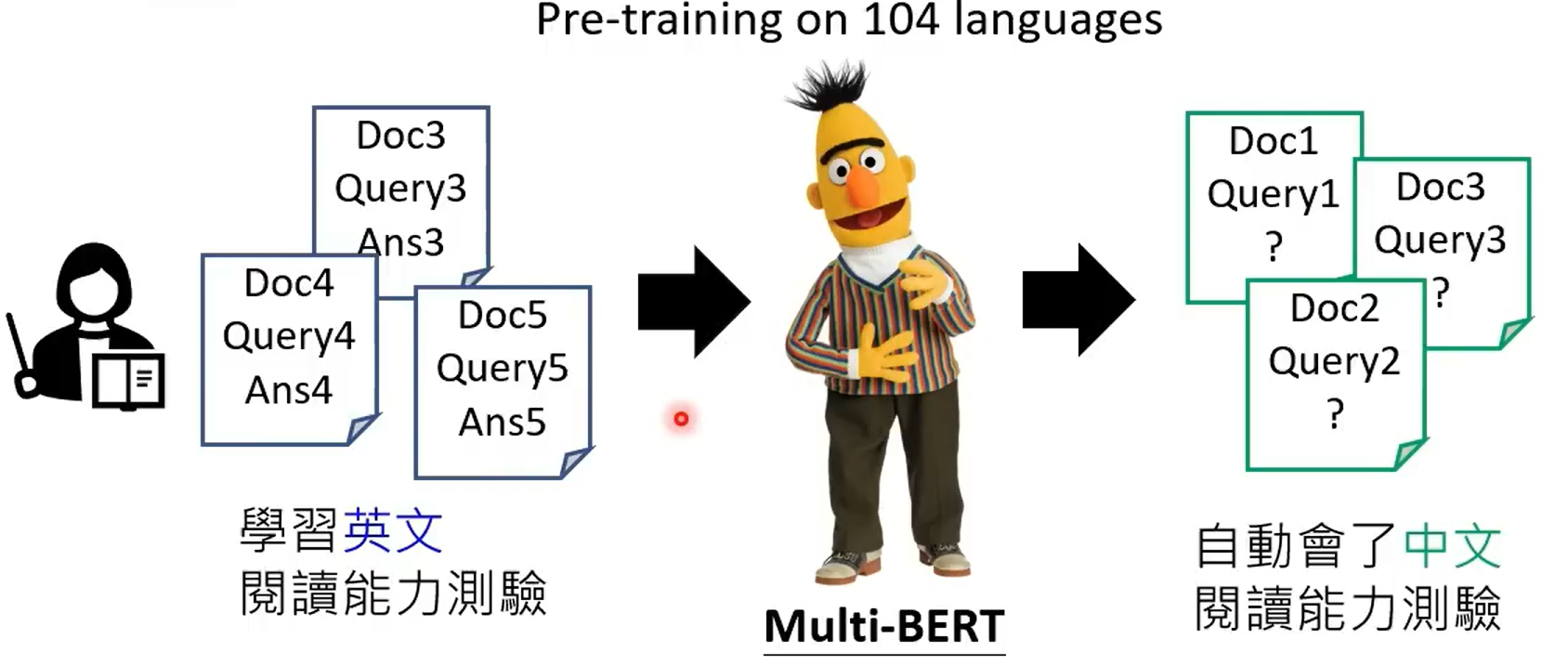
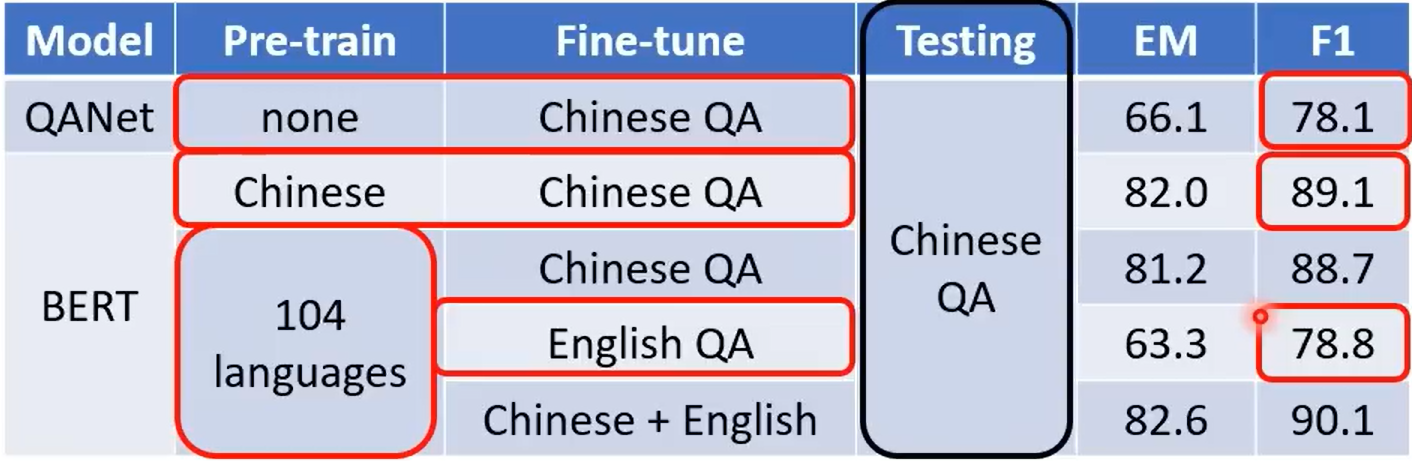
研究结果: English:SQuAD,Chinese:DRCD
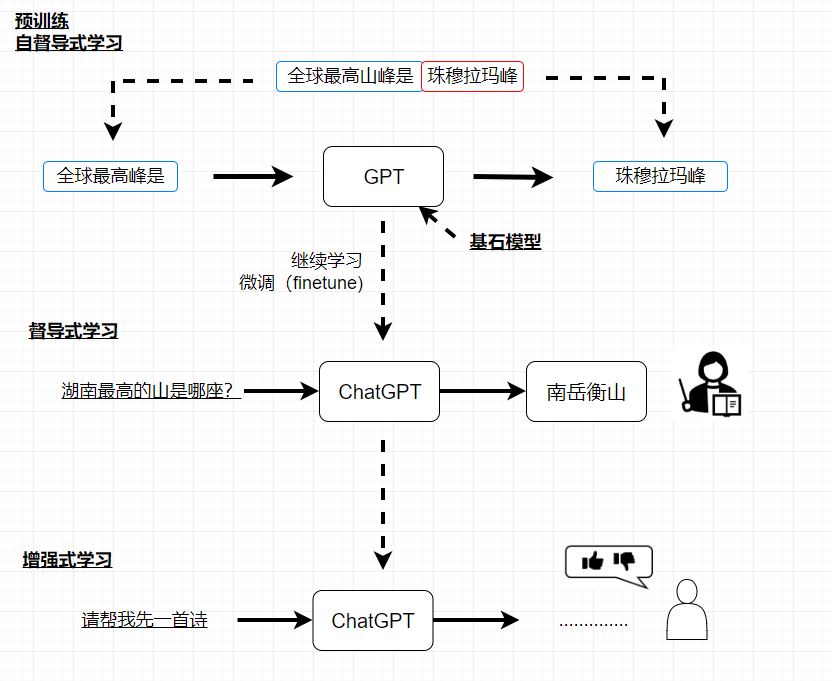
增强式学习(Reinforcement Learning, RL)
ChatGPT不仅有督导式学习,还有增强式学习
人类不是直接给出答案,而是机器给出答案,人类只需要表示好还是不好
相对于督导式学习,增强式学习更加省力,当你想省力的时候就可以使用增强式学习,使用增强式学习的时候可以收集更多的资料,还有一种情况是当人类自己都不知道答案的时候,可以使用增强式学习
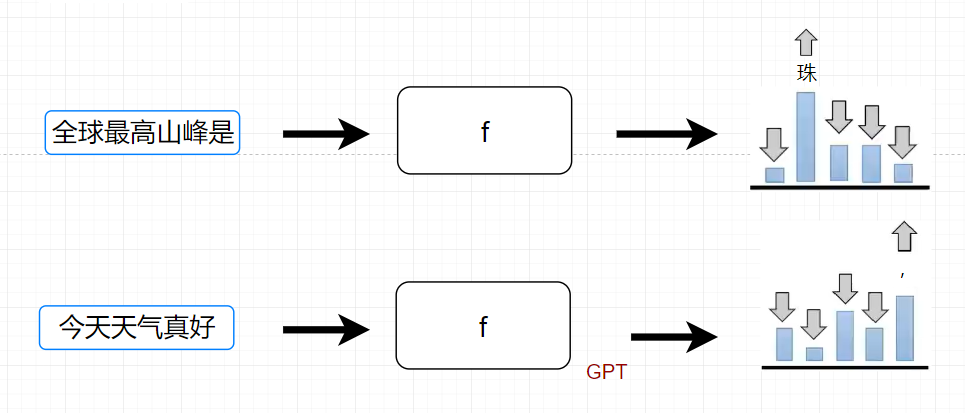
如今ChatGPT也会有前世的记忆
- 看ChatGPT的前世记忆,如下图
上图中的回答开始是一个逗号,这就是它前世的文字接龙