机器学习本质
机器学习 ≈ 机器自动找一个函数
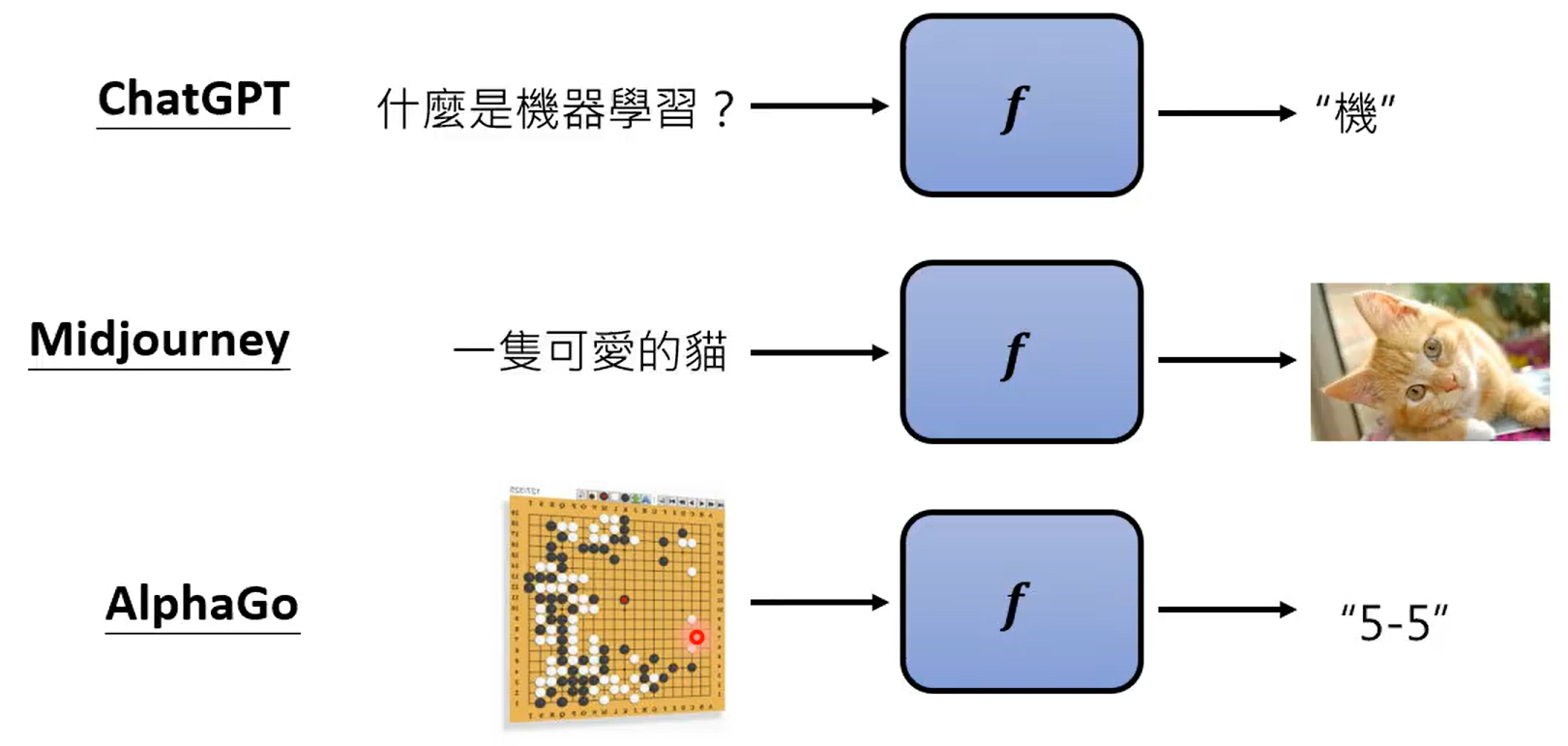
找的函数不同,机器学习的技术有不同的分类
根据函数输出分类
回归(Regression): 函数的输出是一个数值
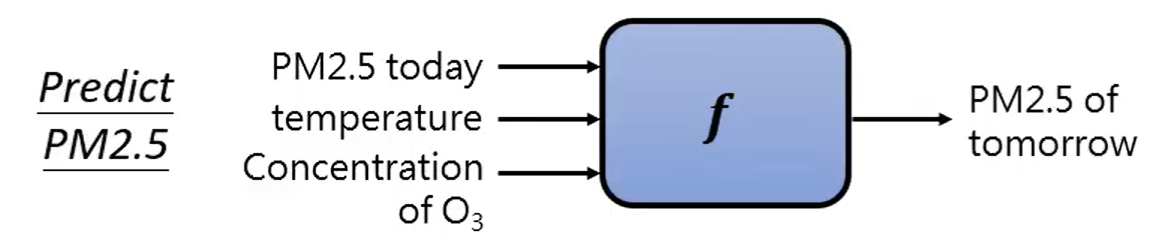
比如要算明天的PM2.5的值, 输入的就是今天PM2.5,今天的气温,今天臭氧浓度等等,输出一个明天PM2.5的值
分类(Classification):函数的输出是一个类别(选择提)
给机器的做选择题,比如下图,给邮件做筛选,输入是一封邮件,输出这封邮件是垃圾邮件还是不是垃圾邮件,是就yes,不是就是no

结构化学习(Structured Learning)
就是要生成有结构的物件(例如:影响、文句)
又叫生成式学习(Generative Learning)
ChatGPT是一个分类的问题,每次进行下一个词汇的预测,判断是或者不是,从这个角度可以说它是一个分类问题;给使用者的感受,使用者输入一个句子,等到回答,它又是一个结构化学习
ChatGPT把生成式学习拆解成多个分类的问题。
找出函数的三步骤
设定范围----设定标准----达成目标
做这个之前有一个前置条件: 决定要找什么样的函数(与技术无关,取决于想要做的应用)
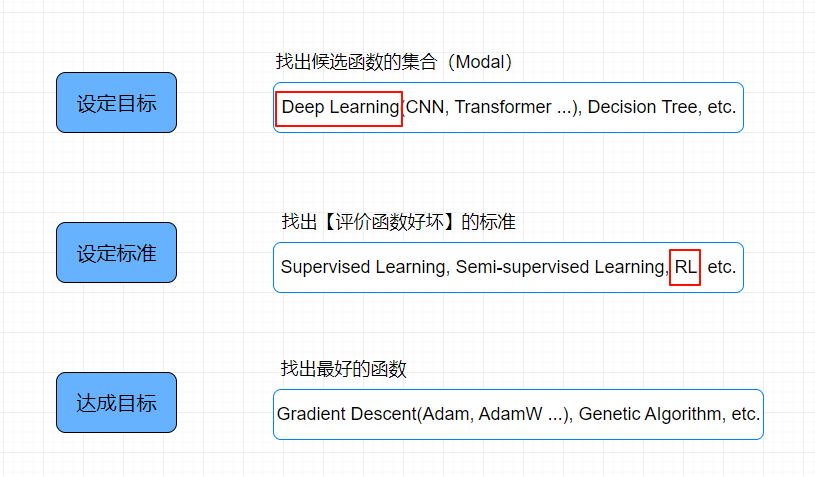
设定范围
找出候选函数的集合(Modal)
深度学习的神经网络的结构(例如:CNN,RNN,Transformer等等)指的就是不同的候选函数的集合
某个内神经网络的结构
设定标准
找出【评价函数好坏】的标准(Loss)
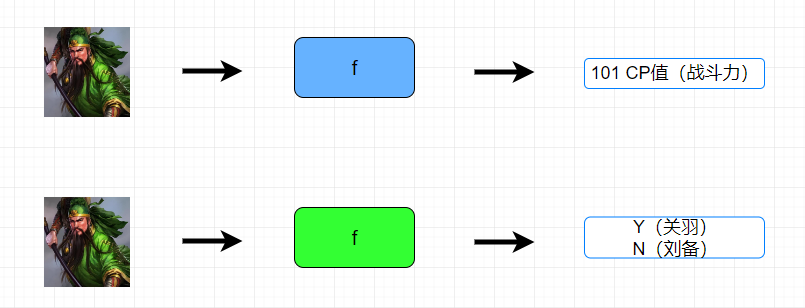
- 要做宝可梦的战斗力的预测,随机找一个函数f1, 丢进三只宝可梦,机器预测出来的战斗力,
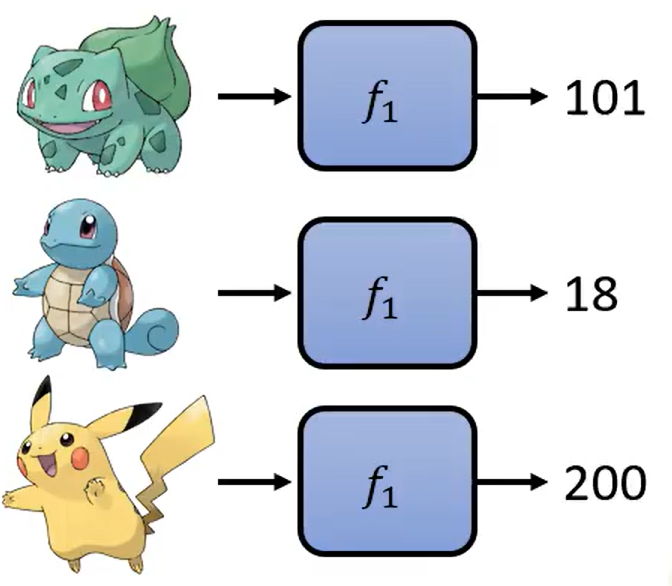
- 当然不知道函数f1预测是不是准的,需要专家给出标准答案,进行标注
此时如果专家给出所有宝可梦的标准答案

- 通过比对函数f1的输出与标准答案,看与标准答案的差距
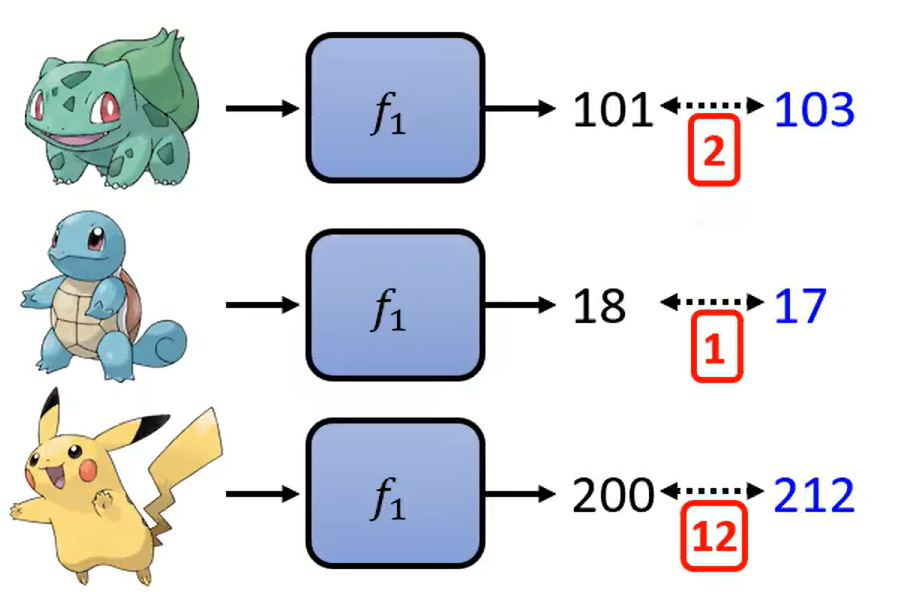
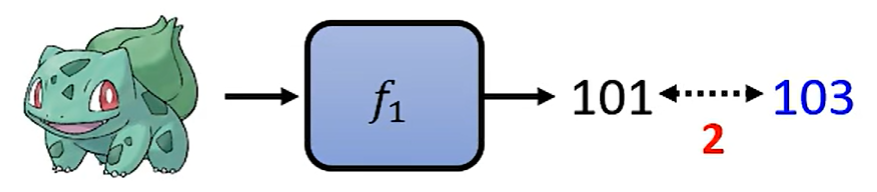
- f1的输出距离正确的答案总和为15,那它的Loss的值就算L(f1) = 15
差距越小函数越好,差距越大函数越不好
L也是一个函数,它的输入是一个函数,所以平时也叫它Loss function
L函数是评价函数好坏的函数
注意: L的计算过程,取决于训练资料
此时如果专家给出部分宝可梦的标准答案
其他是临时加的宝可梦,没有找专家给出标准答案

长的像的宝可梦战斗力要一样
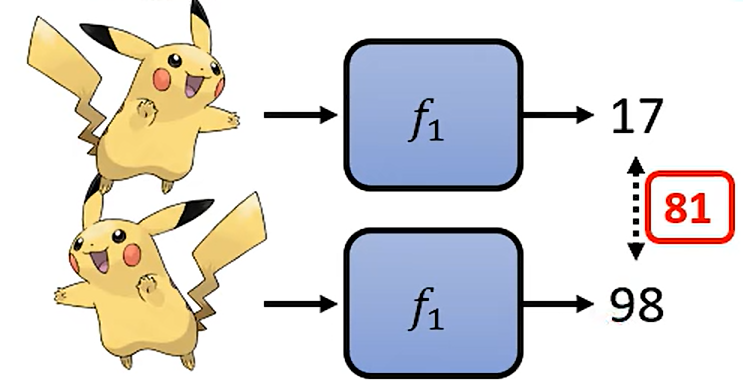
L(f)=输出距离正确答案+长得像的宝可梦差距
根据已有的资料,定标准
达成目标
找出最好的函数 ==> 最佳化(Optimization)
通过上一步的Loss值,确定最好的函数,Loss的值越小函数越好,Loss的值越大函数越不好
有一个集合H,它里面有上游的函数集合,把所有的函数集合代入到L函数,得到Loss值,Loss值最小的那个就是最终函数
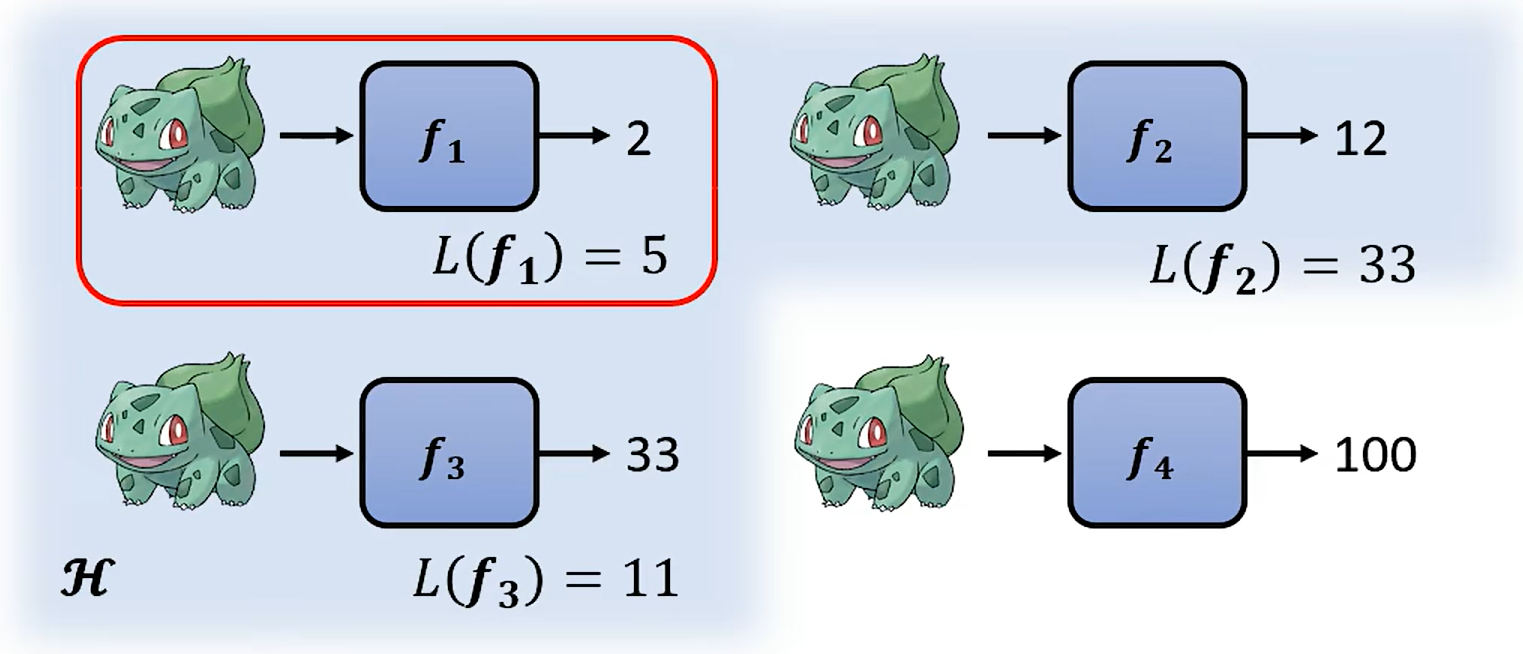
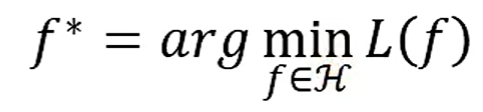
f是H里面的成员,H集合里面的成员会非常多,不会去比较所有的成员,会使用特别的演算来进行寻找,这个演算法是可以是Grandient Descent(Adam,AdamW...)(https://youtu.be/yKKNr-QKz2Q);也有另外一个技巧Backpropagation(https://youtu.be/ibJpTrp5mcE)
小结