生成式学习的两种策略:各个击破和一次到位
生成有结构的复杂物件

复杂物件都是小的元素构成,
比如语句是由token构成,其实就是“字”,token的意思word piece, 是介于词和词汇。比如unbreakable -> un break able(3个word piece)
ChatGPT生成物件的时候,其实是一个分类的问题,就是选择题,需要把所有的选项都列出来
中文的字是比较有机会穷举的,英文词汇是可以是无穷多,比如一个新的人名、新的地名
所以需要把单词或词汇进行拆分成word piece, 因为word piece是可以穷举的,从某种角度,中文更加适合生成式学习
又比如影响是由像素组成, 语音是由16k取样频率,每秒有16000个取样点
生成影片
[Imagen Video]https://arxiv.org/abs/2210.02303
生成影片的样例:https://imagen.research.google/video/

生成语音
生成人的声音

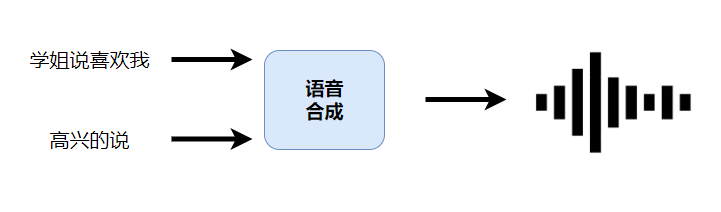
可以通过自然语言去要求它的语气

生成声音
不局限于人声,可以是汽笛声,可以是人跑步声,可以是水滴声

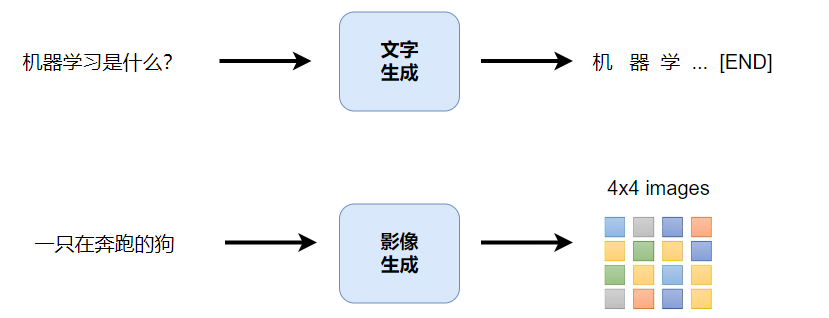
策略1:各个击破 Autoregressive(AR)model
ChatGPT就是各个击破的方式, 给个句子,就一个字一个字的生成出来
生成影像,比如4*4,那就一个像素一个像素生成出来
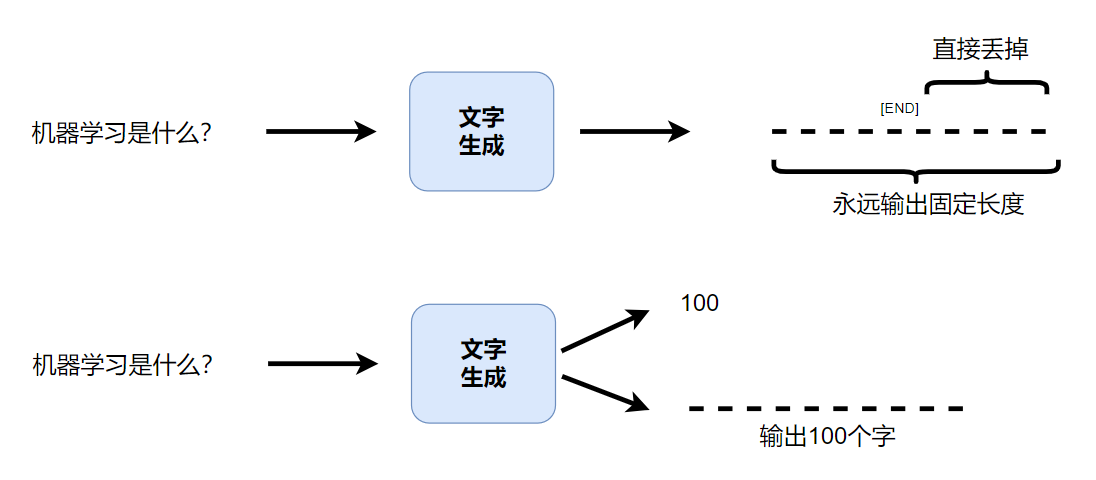
策略2:一次到位 Non-autoregressive(NAR)model
一次把一个句子都输出出来,但是机器不知道要产生多长,这里有2种方法:
第一个方法:每次都输出固定的长度句子,但是这不现实,但是可以在输出的句子中查有没有"END"这个符号,如果有就把后面丢掉,如果没有就继续,这样感觉每次问的答案的长短都不一样
第二个方法:文字生成的模型输出一个数字,这个数字就是接下来要输出内容的长度
各个击破 vs 一次到位
生成速度
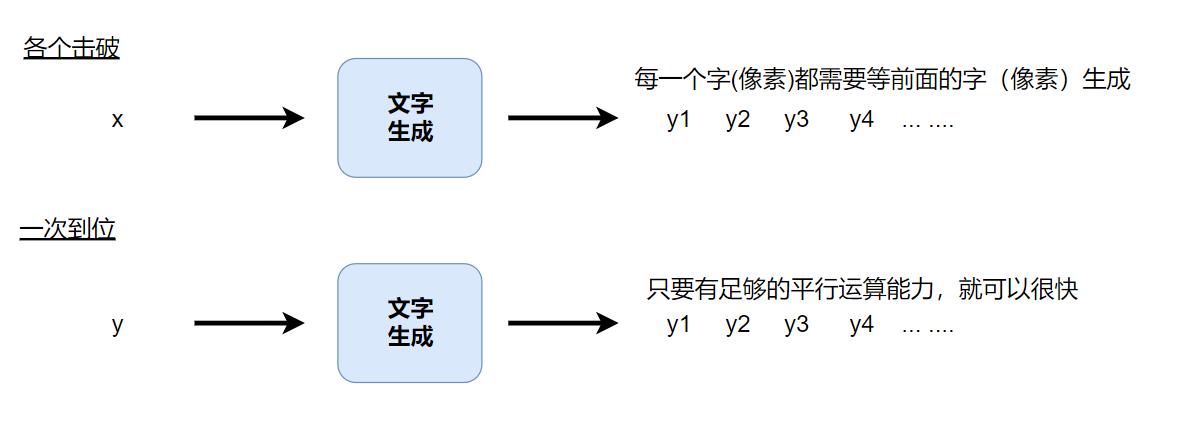
这就是为什么影像生成常用【一次到位】,相较文字,影像的元素更多。一张100*100图片,就有10000个像素,这个100*100图片还是画质比较低的。
生成质量
各个击破的生成的质量比较高,一次到位的质量相对较差
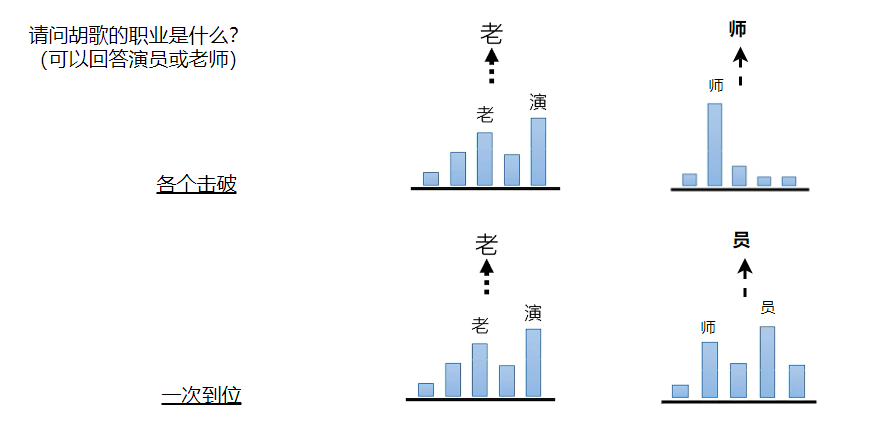
比如:请问胡歌的职业是什么?
如果是各个击破,机器会先产生的是一个机率的分布,从这个机率分布里面去做sampling(概率分布中抽取样本),开始问这个问题的时候,机器弄不清楚问的是哪个胡歌,第一个答案“演”的机率会很高,“老”的机率也会很高,假设“老”被选出来,因为sampling不一定是机率最高的,所以后面接的是“师”
如果是一次到位,一次把所有的分布都产生出来,第一个生成位置“老”和“演”的机率都会很高,第二个位置“师”和"员"的机率也会很高,接下来再做sampling,就有可能生成"老员",这就不是想要的
对比表
| 各个击破(Autoregressive,AR) | 一次到位(Non-autoregressive,NAR) | |
|---|---|---|
| 速度 | 胜 | |
| 质量 | 胜 | |
| 应用 | 常用于文字 | 常用于影像 |